
เมื่อ Azure คือต้นเหตุ Microsoft 365 ล่มทั่วโลก – เกิดอะไรขึ้นกับระบบคลาวด์ของไมโครซอฟท์?

เมื่อวันที่ 9 ตุลาคมที่ผ่านมา ผู้ใช้ Microsoft 365 ทั่วโลก ต้องเผชิญเหตุขัดข้องครั้งใหญ่ บริการสำคัญอย่าง Outlook, Teams, OneDrive, SharePoint และ Entra ID (Azure AD เดิม) ไม่สามารถใช้งานได้หลายชั่วโมง สร้างผลกระทบต่อองค์กรจำนวนมาก ทั้งภาครัฐและเอกชน
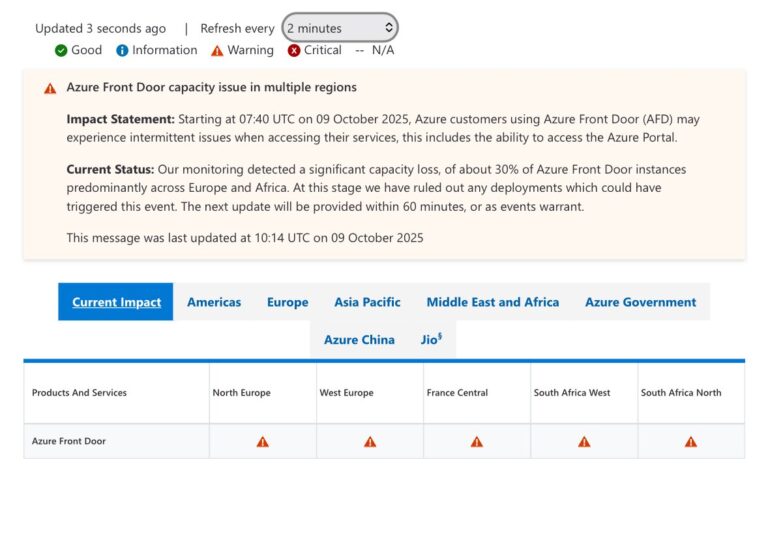
โดยเว็บไซต์ Downdetector แสดงการรายงานปัญหาพุ่งสูงในหลายภูมิภาค ขณะที่โซเชียลมีเดียเต็มไปด้วยข้อความร้องเรียนจากผู้ใช้ทั่วโลก ไมโครซอฟท์ยืนยันในเวลาต่อมาว่า สาเหตุของเหตุการณ์นี้มาจาก Azure Front Door (AFD) — บริการกระจายทราฟฟิก (Content Delivery Network) ที่เป็นหัวใจของระบบคลาวด์ของบริษัท
Azure Front Door ขัดข้อง ทำให้โครงสร้างหลักของระบบล่ม
จากข้อมูลใน Azure Status Page ระบุว่า ปัญหาเกิดจาก การสูญเสียความจุ (capacity loss) ประมาณ 30% ของระบบ Azure Front Door ในบางภูมิภาค โดยเฉพาะยุโรป แอฟริกา และตะวันออกกลาง ส่งผลให้ผู้ใช้ไม่สามารถเชื่อมต่อบริการในเครือ Microsoft 365 และ Azure ได้
Azure Front Door คือโครงสร้างที่ทำหน้าที่เป็น “ด่านหน้าของระบบ” ใช้สำหรับกระจายทราฟฟิกจากผู้ใช้ไปยังเซิร์ฟเวอร์ที่เหมาะสมที่สุดทั่วโลก เมื่อระบบนี้เกิดความขัดข้อง จึงส่งผลกระทบเป็นลูกโซ่ต่อบริการทั้งหมดที่พึ่งพาโครงสร้างนี้ เช่น Microsoft 365, Entra ID, Azure Portal และ Intune Admin Portal
ไมโครซอฟท์ระบุว่า ไม่ใช่ความผิดพลาดจากการอัปเดตซอฟต์แวร์หรือโค้ดใหม่ แต่เป็นความผิดพลาดเชิงโครงสร้างในระบบ orchestration ของ Kubernetes ภายใน AFD ซึ่งกระทบการตรวจสอบสถานะ (health probe) ของโหนด ทำให้ระบบกระจายโหลดล้มเหลวและส่งผลต่อผู้ใช้ทั่วโลก
การรับมือของไมโครซอฟท์
ในวันที่ 9 ตุลาคม ไมโครซอฟท์ตรวจพบปัญหาครั้งแรกเมื่อเวลา 07:40 UTC (14:40 น. ตามเวลาไทย) และเริ่มดำเนินการ reroute ทราฟฟิกออกจากโหนดที่มีปัญหา พร้อม รีสตาร์ทอินสแตนซ์ Kubernetes ภายในระบบ AFD เพื่อฟื้นฟูความจุให้กลับมาทำงาน
ในเวลา 16:00 UTC (23:00 น. ตามเวลาไทย) ระบบส่วนใหญ่เริ่มกลับมาทำงานตามปกติ โดยบริการอย่าง Outlook และ Teams กลับมาออนไลน์อีกครั้ง แต่ยังมีผู้ใช้บางส่วนในยุโรปและเอเชียรายงานการเข้าถึง Azure Portal ล่าช้าอยู่
ไมโครซอฟท์ระบุว่าทีมวิศวกรได้เฝ้าติดตามสถานการณ์อย่างใกล้ชิด พร้อมอัปเดตสถานะทุก 60 นาที ผ่าน Azure Status Page และช่องทาง @MSFT365Status บน X (Twitter)
เหตุการณ์นี้ตอกย้ำว่า แม้ระบบคลาวด์จะมีความยืดหยุ่นสูง แต่หากมี “จุดศูนย์กลางเดียว (single point of failure)” ก็สามารถทำให้บริการทั่วโลกหยุดชะงักได้ในพริบตา
- จุดศูนย์กลางคือจุดเปราะบางที่สุด
Azure Front Door เป็นหัวใจของการเชื่อมต่อทั้งหมด เมื่อมันสะดุด ระบบอื่นจึงล่มตามแบบโดมิโน - การออกแบบระบบต้องมีเส้นทางสำรอง (failover / multi-region)
เพื่อให้สามารถเปลี่ยนเส้นทางการให้บริการอัตโนมัติในกรณีที่บางภูมิภาคเกิดปัญหา - ระบบตรวจสอบต้องละเอียดถึงระดับ edge node
เพื่อให้สามารถตรวจจับปัญหาได้ก่อนที่จะกระทบผู้ใช้ปลายทาง - ความโปร่งใสคือสิ่งสำคัญในยามวิกฤต
การอัปเดตสถานะทุกชั่วโมงของไมโครซอฟท์ได้รับคำชมจากลูกค้าหลายรายว่า “ช่วยลดผลกระทบทางธุรกิจได้มาก”