
เบื้องหลังเหตุการณ์ AWS ล่มครั้งประวัติศาสตร์ จุดตายเพียงจุดเดียว สู่หายนะวงกว้างที่แม้แต่ AI ก็รับมือไม่ไหว

Amazon Web Services (AWS) ได้ออกมาเปิดเผยสาเหตุเบื้องหลังเหตุการณ์ระบบล่มครั้งใหญ่เมื่อวันที่ 20 ตุลาคม 2025 ที่ผ่านมา ซึ่งส่งผลกระทบเป็นวงกว้างต่อบริการออนไลน์ทั่วโลกยาวนานกว่า 15 ชั่วโมง โดยต้นตอของปัญหามาจาก “จุดตายเพียงจุดเดียว” (Single Point of Failure) ซึ่งเป็นข้อบกพร่องเล็กน้อยในระบบซอฟต์แวร์ที่ทำงานอัตโนมัติ ก่อนจะลุกลามจนกลายเป็นหายนะแบบลูกโซ่ที่ทำให้แม้แต่ระบบ AI อัจฉริยะของ Amazon เองก็ไม่สามารถรับมือได้
จุดเริ่มต้นของหายนะ: Race Condition ในระบบ DNS
จากการวิเคราะห์ของ Amazon พบว่า ต้นเหตุของวิกฤตครั้งนี้เกิดจากข้อบกพร่องที่ซ่อนอยู่ในระบบจัดการ Domain Name System (DNS) อัตโนมัติของบริการฐานข้อมูลสำคัญอย่าง DynamoDB ในศูนย์ข้อมูล US-EAST-1 ที่นอร์ทเวอร์จิเนีย ซึ่งเป็นหนึ่งในภูมิภาคที่ใหญ่และเก่าแก่ที่สุดของ AWS
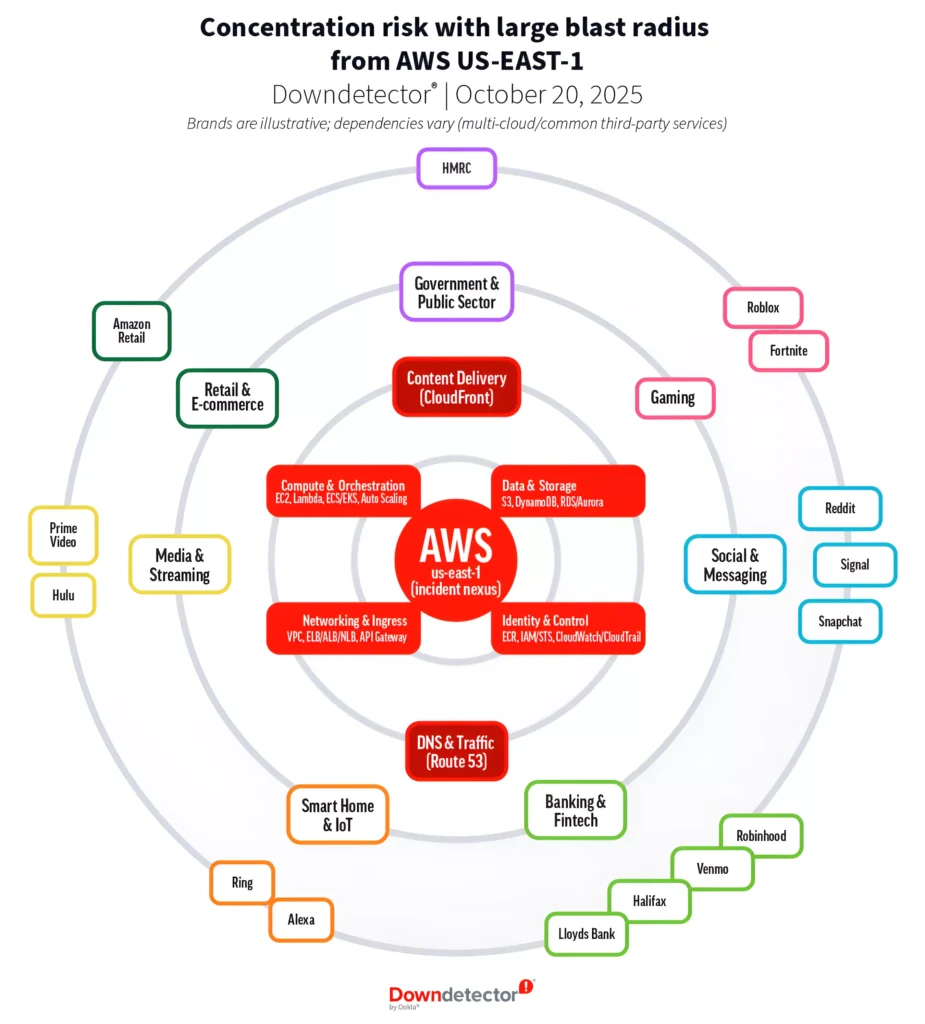
โดยปกติแล้ว ระบบนี้จะคอยอัปเดตและจัดการระเบียน DNS หลายแสนรายการเพื่อกระจายภาระการทำงานและรับมือกับความผิดพลาดของฮาร์ดแวร์ แต่ในวันเกิดเหตุ ได้เกิดสภาวะที่เรียกว่า “Race Condition” ขึ้น ซึ่งเป็นข้อบกพร่องที่เกิดขึ้นเมื่อโปรแกรมตั้งแต่สองตัวขึ้นไปพยายามแก้ไขข้อมูลเดียวกันในเวลาเดียวกัน ส่งผลให้ระเบียน DNS ของ DynamoDB กลายเป็นค่าว่างและทำให้บริการฐานข้อมูลดังกล่าวไม่สามารถเข้าถึงได้
ผลกระทบแบบโดมิโน่ สู่การล่มสลายวงกว้าง
เมื่อ DynamoDB ซึ่งเป็นหัวใจของบริการหลักอื่นๆ ของ AWS หยุดทำงาน ได้ก่อให้เกิดผลกระทบแบบโดมิโน่อย่างรวดเร็ว บริการสำคัญอย่าง EC2 (ระบบประมวลผล), IAM (ระบบยืนยันตัวตน) และ Network Load Balancers ที่ต้องพึ่งพา DynamoDB ในการทำงานก็ล้มเหลวตามไปด้วย
ผลลัพธ์คือหายนะทางอินเทอร์เน็ตที่แผ่ขยายไปทั่วโลก แอปพลิเคชันและเว็บไซต์ยอดนิยมหลายพันแห่ง ตั้งแต่บริการสตรีมมิงอย่าง Netflix, แอปสนทนาอย่าง Slack และ Snapchat, แพลตฟอร์มเกม Roblox ไปจนถึงบริการของธนาคาร, สายการบิน และแม้แต่อุปกรณ์ในบ้านอัจฉริยะอย่างกริ่งประตู Ring และเตียงนอนอัจฉริยะก็ไม่สามารถใช้งานได้ เว็บไซต์ Downdetector บันทึกรายงานปัญหาจากผู้ใช้กว่า 17 ล้านครั้ง จากกว่า 3,500 บริษัททั่วโลก นับเป็นหนึ่งในการล่มครั้งใหญ่ที่สุดที่เคยบันทึกมา
เมื่อ AI ก็เอาไม่อยู่
สิ่งที่น่าสนใจคือ แม้ Amazon จะมีระบบ Predictive Health Engine ซึ่งเป็น AIOps (AI for IT Operations) ที่คอยวิเคราะห์และแก้ไขปัญหาที่อาจเกิดขึ้นล่วงหน้า แต่ในสถานการณ์นี้ ระบบ AI ดังกล่าวกลับไร้ประโยชน์
เนื่องจากระบบ AI เองก็ต้องพึ่งพาสภาพแวดล้อม DNS และโครงสร้างพื้นฐานเดียวกับที่ล่มสลายไป ทำให้มัน “ตาบอด” ไม่สามารถรับข้อมูลที่ถูกต้องเพื่อวิเคราะห์สถานการณ์ได้ การพยายามแก้ไขปัญหาอัตโนมัติของ AI กลับทำให้สถานการณ์เลวร้ายลง โดยไปเพิ่มภาระการจราจรข้อมูลในระบบที่ล้มเหลวอยู่แล้ว จนในที่สุดวิศวกรต้องเข้ามาแทรกแซงและปิดระบบ AI เพื่อควบคุมสถานการณ์ด้วยตนเอง
หลังเหตุการณ์สงบลง Amazon ได้ออกมาขอโทษผู้ใช้บริการ พร้อมทั้งปิดการใช้งานระบบ DNS อัตโนมัติที่เป็นปัญหาทั่วโลกเป็นการชั่วคราว เพื่อแก้ไขข้อบกพร่องและเพิ่มมาตรการป้องกันเพิ่มเติม เหตุการณ์ครั้งนี้ถือเป็นบทเรียนสำคัญที่ชี้ให้เห็นว่า แม้แต่ในระบบคลาวด์ที่ใหญ่และทันสมัยที่สุดในโลก ก็ยังมีความเปราะบางจากจุดบกพร่องเพียงจุดเดียวได้